
Compilers Pt. 2 -- Parsing
[In Progress] Parsing is where the compiler determines the validity of an input programs syntax. Context Free Grammars, Parse Trees, and more are covered here.


Parsing
Parsing is a process that is performed by a compiler as part of the frontend, in which it analyzes the syntax of the source code to determine its structure and meaning. The parser is responsible for verifying that the source code follows the rules of the programming language and generating a representation of the code that can be used by other parts of the compiler. To do so, we have to have some way to represent the syntax rules of our source programming language. We have already seen one potential candidate in Regular Expressions. Sadly, RE's are lacking expressivity in a few areas, one of which being operator precedence (you know? the whole PEMDAS thingy?). Another shortcoming of Regexes is the fact that they are incapable of reliably matching brackets crucial to many constructs such as if-else statements.
Instead, we use a separate notation called Context Free Grammars (CFGs). CFGs are essentially collections of rules enumerating acceptable sentences. Similar English rules has in definition what makes valid sentence [sorry for the minor stroke there, what I meant was: Similarly, in English there are defined rules as to what constitutes a valid sentence]. CFGs consist of variables called nonterminal symbols and syntactic-categories called terminal symbols. The rules of CFGs explicate which nonterminal symbols derive (read "define") which combination of {non}terminal symbols. More formally, CFGs are 4-tuples of the set of terminal symbols, the set of nonterminal symbols, the set of sentences in the language, and the set of rules. However, for our purposes the formal definition is a bit heady.
To hand-wave over the process of sentence derivation, we start our prototype sentence with some start symbol, and pick a nonterminal symbol to try to resolve according to it's grammar rule, and loop until the sentence consists of only terminal symbols. Once we're done, we check the sentences validity and accept it if it's valid ("sentential form").
For example: say we wanted to represent an expression. We would define the nonterminal symbols Expr and Op as follows:
Expressions:
1. Expr -> ( Expr )
2. | Expr Op Expr
3. | name
Operators:
4. Op -> +
5. | -
6. | *
7. | /
Or in words, an expression can be preceded and succeeded by a pair of parentheses, or it can be a pair of expressions combined with some operator, or it can just be the name of a variable. Everywhere on the right-hand side where you see "Expr", you can recursively expand. For a particular example, this recursive expansion can be illustrated using parse trees. Let's take a look at the expression (a+b) * c:
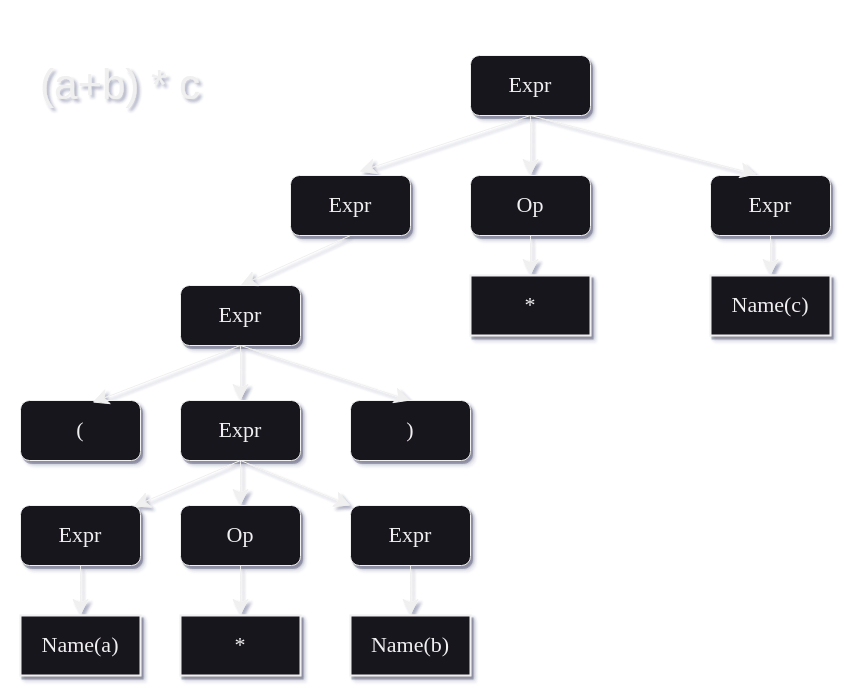
- At the root node of the tree we have the whole expression "(a+b) * c"
- This is expanded on the next level down according to rule 2: Expr Op Expr => [(a+b)] [*] [c]
- On the left hand side expression, we can expand according to rule 1: ( Expr ) => [(] [a+b] [)]
- The inner expression can then be expanded according to rule 2: Expr Op Expr => [a] [+] [b]
- Then the inner left expression can be resolved to the name (variable) 'a'
- The inner operator can be resolved to the Op '+'
- The inner right expression can be resolved to the name (variable) 'b'
- The outer operator can be resolved to the Op '*'
- The rightmost expression can be resolved to the name (variable) 'c'
As we derive each sentence, it is important that we keep track of which rules we applied along the way -- this is what we will use to represent the parse tree. Although we derived from left to right, we can instead go the opposite direction. Even though the order changes, the set of rules applied will not change (and should be unique as long as the grammar is unambiguous).
This particular grammar happens to struggle with ambiguity without the aid of parentheses as it fails to take into account operator precedence. In the case of "a + b * c", order matters. Sadly, the actual CFG's we use in C0's compiler won't be as simple as that one.
The tokens generated by the scanner represent the leaf nodes of each corresponding sentence's parse tree. Simultaneously, we know the root node of the parse tree, as it is given by the grammar's start symbol. When parsing, our goal is to figure out what makes up the middle (or branches of the tree). Therefore we are presented yet another design choice: where to start?
There are two main approaches to parsing: top-down parsing and bottom-up parsing.
Top-down parsing involves placing the start symbol at the root of the parse tree and constructing the branches of the tree by expanding our nonterminal symbols until we end up with a series of leaf nodes matching the sentence of tokens in our input. Note that token sentences in C0 are typically terminated by the separator token ';'. We work from the top of the tree down to the leaves. At each cycle, the parser has to choose which productions to use to expand nonterminals.
There are a few options when parsing from the top-down. The first choice we have to make is whether we mind backtracking. When selecting productions, if we choose the wrong production we won't match the token sentence and we will have to back track our steps and try another sequence of productions. If we don't mind backtracking, we can use a brute force parse. Of course, this can prove incredibly inefficient. In most cases, we will want to backtrack as little as possible. There are a few options to intelligently parse from the top-down: recursive descent parsing, and predictive parsing (LL(1), and LL(K)).
By choosing to parse from the top-down, we are making the bet that we will make the right guess of which production to expand more often than not. When we get this guess wrong, we have to roll back and try again. If we aren't able to rig the die in our favor, this guess and check style can become quite costly. Loaded die in top-down parsing are called backtrack-free or predictive grammars. Many CFGs fit into this category.
Bottom-up parsing involves starting with the individual tokens of the source code and constructing the syntax tree by combining them into larger and larger groups, working from the leaves of the tree up to the root. When parsing from the bottom-up, we have a few choices: Operator precedence parsers, or LR Parsers (LR(0), SLR(1), LALR(1), CLR(1)).
Placeholder:
*This is often done using a shift-reduce parser, which reads the input tokens one at a time and decides whether to shift them onto a stack or to reduce them using a production rule from the grammar of the programming language.
As with scanners, there are parser generators where you simply input the grammar, and get a parse in return. For our C0 parser, we will instead write it by hand, selecting a top-down recursive descent parser. A recursive descent parser reads the input tokens, then expands productions via recursive function calls. For example, a simple recursive descent parser for the following grammar:
A -> iB
B -> +iB
| ε
fn A() {
if tokens.peek() == Tokens::Id(Id::Id('i'.to_string())) {
tokens.next();
B();
}
}
As you can see, nonterminal symbols have corresponding functions. The hard part is defining your CFG efficiently.
After the parsing process is complete, we will do one final spot check to ensure that any potential erroneous code doesn't make it through.